All Activity
- Past hour
-
 AlphaLab joined the community
AlphaLab joined the community - Today
-
Just find MrExodia's src he shared some years ago and update it for the new enigma versions.
-
 kodenium joined the community
kodenium joined the community -
 whitenul joined the community
whitenul joined the community - Yesterday
-
 r3l4h joined the community
r3l4h joined the community -
 suntzun joined the community
suntzun joined the community -
I'm trying to learn the bypass technique with shfolder.dll, but I can't find any complete information, can anyone help me?
-
 kino123 joined the community
kino123 joined the community -
 ChoVinisTa joined the community
ChoVinisTa joined the community -
Hello. Are there any beginner tutorials on how to go about decompiling and reversing the donNet reactor? I'd like to follow these unpackme's, but I'm unsure where to start. On Windows here. Much of what I see uses Linux. Any pointers would be much appreciated.
-
- Last week
-
Amazing work @Washi ! Explained it nice and clear (from start to finish), and regarding the multiple "solutions" it is intended, yes Great work , quite impressive to see solutions well "versed" like yours , good job ! Greetings !
-

What is the answer to your security question?
Progman replied to tonyweb's topic in Site Bug Reports and Feedback
The answer to my security question is "The Magic Words are Squeamish Ossifrage". Why do you ask? -
Your crackme seems to have multiple solutions. Not sure if this was intended: Some example passwords: Approach:

-
To contact, email me at: remipsprj@treissoft.com
-
Seeking a skilled, versatile reverse engineer primarily working with PSP and PS1 emulators, MIPS architecture and various binary game formats ranging from textures, compressed LZTX archives special FX modifying, GUI tools, script decompilation and recompilation RPG mathematics and system editing, text string editing and more, Strong written and oral communication skills Must work well Must possess strong organizational and time management skills Demonstrate flexibility and ability to adapt Requirements: Experience with C++, C programming Software engineering Low-level concepts Educated guessing Deep reverse engineering experience with video games and complex binary formats Able to create tools effectively handling game data. Game Programming experience in create software and tools and UI interfaces. Effectively communicate and work successfully. Can follow directions and instructions clearly. Self-motivation and a willingness to take initiative Experience with other programming languages (python, C#, etc.) IDA Pro, Binary Ninja, Ghidra or other reverse engineering tools Extensive experience with reverse engineering programming Completion of one or more years of undergraduate coursework in Computer Science, Game Development, Mathematics, Engineering, or related discipline. Game Programming experience in create software and tools and UI interfaces. Experience with video game consoles, emulators and API including Vulkan and OpenGL. Extensive experience with reverse engineering programming. Completed courses and understanding of 3D math. Document and NDA agreement. (Required). Milestone based, immediate half upfront after overview, half after completed. Starting immediately.
-
Greetings, if "YOU" are so "PARANOID" , just run it in a "VM" , i can tell you "1" thing , its completely safe. So, i don't know where your getting this garbage | bullshit , from. And there is "virustotal" for a reason ! The only weird things is , you making these stupid remarks about this challenge.... ! Regarding the false accusations thrown about... Nor does this challenge require internet. No HTTP/s communication | In-between, whatsoever. Greetings !
-
Yeah something aint right about this crackme. Also once you get into here you will find quite more interesting things like hostname checking and so on. Not 100% sure but be aware of where you are executing "new" crackmes by "V0KsISsSs" friend.
-
I didn't run in VM, but on real machine.
-
@CodeExplorer Hey Code,did you run this in VM?
- Earlier
-
Excellent write-up. It is complete and easy to understand. Thank you
-
On the 000000014000838B 0, 1, 2, 3 8, 9, A, B, C, D, 6, 7 - 0000000140008BD4 | 8B4424 20 | mov eax,dword ptr ss:[rsp+20] 0000000140008BD8 | FFC0 | inc eax 0000000140008BDA | 894424 20 | mov dword ptr ss:[rsp+20],eax 0000000140008BDE | E9 07070000 | jmp crackme123.1400092EA 0000000140008A16 | 8B4424 30 | mov eax,dword ptr ss:[rsp+30] | 0000000140008A1A | FFC0 | inc eax | 0000000140008A1C | 894424 30 | mov dword ptr ss:[rsp+30],eax | 0000000140008A20 | 837C24 30 04 | cmp dword ptr ss:[rsp+30],4 | 0000000140008A25 | 0F8D A9010000 | jge crackme123.140008BD4 | 0000000140008A2B | 8B4424 24 | mov eax,dword ptr ss:[rsp+24] | 0000000140008A2F | 99 | cdq | 0000000140008A30 | 83E2 03 | and edx,3 | 0000000140008A33 | 03C2 | add eax,edx | 0000000140008A35 | 83E0 03 | and eax,3 | 0000000140008A38 | 2BC2 | sub eax,edx | 0000000140008A3A | 898424 80000000 | mov dword ptr ss:[rsp+80],eax | 0000000140008A41 | 83BC24 80000000 00 | cmp dword ptr ss:[rsp+80],0 | 0000000140008A49 | 74 2B | je crackme123.140008A76 | 0000000140008A4B | 83BC24 80000000 01 | cmp dword ptr ss:[rsp+80],1 | 0000000140008A53 | 74 60 | je crackme123.140008AB5 | 0000000140008A55 | 83BC24 80000000 02 | cmp dword ptr ss:[rsp+80],2 | 0000000140008A5D | 0F84 90000000 | je crackme123.140008AF3 | 0000000140008A63 | 83BC24 80000000 03 | cmp dword ptr ss:[rsp+80],3 | 0000000140008A6B | 0F84 C3000000 | je crackme123.140008B34 | 0000000140008A71 | E9 0B010000 | jmp crackme123.140008B81 | 0000000140008A76 | 8B4424 30 | mov eax,dword ptr ss:[rsp+30] | 0000000140008A7A | D1E0 | shl eax,1 | 0000000140008A7C | 48:98 | cdqe | 0000000140008A7E | 48:898424 E8010000 | mov qword ptr ss:[rsp+1E8],rax | 0000000140008A86 | 48:8D8C24 98000000 | lea rcx,qword ptr ss:[rsp+98] | 0000000140008A8E | E8 0DEDFFFF | call crackme123.1400077A0 | so I don't any idea where the password test is made...
-
It is 64 bit file, so I load the file in x64dbg print Incorrect password: 000000014000593E | E8 FDBCFFFF | call crackme123.140001640 | 0000000140005943 | 48:894424 48 | mov qword ptr ss:[rsp+48],rax | 0000000140005948 | 48:8D15 81CFF | lea rdx,qword ptr ds:[1400028D0] | 000000014000594F | 48:8B4C24 48 | mov rcx,qword ptr ss:[rsp+48] | 0000000140005954 | E8 97E4FFFF | call crackme123.140003DF0 | 0000000140005959 | 48:83C4 78 | add rsp,78 | 000000014000595D | C3 | ret | called from here: 000000014000838B | 8B4424 20 | mov eax,dword ptr ss:[rsp+20] | 000000014000838F | 898424 B80000 | mov dword ptr ss:[rsp+B8],eax | 0000000140008396 | 83BC24 B80000 | cmp dword ptr ss:[rsp+B8],31 | 31:'1' 000000014000839E | 0F87 3C0F0000 | ja crackme123.1400092E0 | 00000001400083A4 | 48:638424 B80 | movsxd rax,dword ptr ss:[rsp+B8] | 00000001400083AC | 48:8D0D 4D7CF | lea rcx,qword ptr ds:[140000000] | 00000001400083B3 | 8B8481 B09300 | mov eax,dword ptr ds:[rcx+rax*4+93B0] | 00000001400083BA | 48:03C1 | add rax,rcx | 00000001400083BD | FFE0 | jmp rax | but I don't know which is proper valid value of dword ptr ss:[rsp+B8]
-
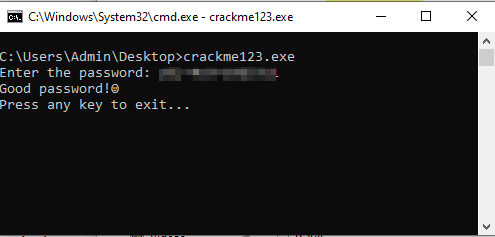
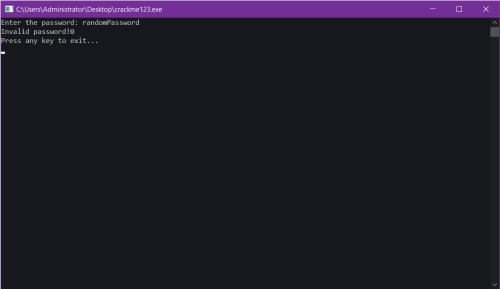
View File crackme123 A "Crack Me" challenge created by lord "Voksi" , a well known person in the "warez" scene. And no, this challenge is not uploaded by "Voksi" himself, it's uploaded via a proxy which is myself, an old friend of "Voksi" . GOAL: Obtain the Correct key Greetings to MasterBootRecord, Voksi, FJLJ, And also a few others, you know who you are ❤️ Submitter casualPerson Submitted 07/04/2025 Category CrackMe
-
 Hi, I sent me reg today m!x0r thanks
Hi, I sent me reg today m!x0r thanks -
V-S-2-0-1-2
-
VS2012? Typo for VS2022?
-
 casualPerson changed their profile photo
casualPerson changed their profile photo -
34 downloads
A "Crack Me" challenge created by lord "Voksi" , a well known person in the "warez" scene. And no, this challenge is not uploaded by "Voksi" himself, it's uploaded via a proxy which is myself, an old friend of "Voksi" . GOAL: Obtain the Correct key Greetings to MasterBootRecord, Voksi, FJLJ, And also a few others, you know who you are ❤️ -
Release.rar VS2012 Community Edition
-
Which compiler do you use? Can you send it again but with the original compiler output file?
-
yes crt