All Activity
- Yesterday
-
 moodduckk joined the community
moodduckk joined the community -
 adrianowkr joined the community
adrianowkr joined the community -
 rarara papa joined the community
rarara papa joined the community -
3.9.5 changes protection against unpacking and improved anti debug, from that leak all unpack and critical vulnerability before 3.9.2 allowed change serial vmp license ultimate version in memory
-
congrats @CreateAndInject here is the source incl refs @ WindowsFormsApplication37-src.rar
-
unpacked.exe
-
pls explain this interesting statement!
-
They have fixed the source leak in vmp 3.95 so back to the drawing board Also 3.8 had a memory leaking issue, which I haven’t checked to see if it’s been fixed
-
 Laozhihua joined the community
Laozhihua joined the community -
 Bernd677 joined the community
Bernd677 joined the community -
 CKeyP8 joined the community
CKeyP8 joined the community -
Is the Charm
- Last week
-
 mkbl92 joined the community
mkbl92 joined the community -
...because cloning git repo, or just clicking on anonfiles.com_d1D7M7q9z4_vmpsrc.zip is so f*ing complicated. You don't need VMProtect sources. What you need is a basic understanding of this magical thing called "the internet".
-
wow! someone is cheating with us here! (sneaky snitch) 2nd time https://www.sendspace.com/file/51jvil
-
This file has been banned
-
copy from pixadrain - https://workupload.com/file/MqvBWJnEM9K
-
 erger joined the community
erger joined the community -
https://github.com/jmpoep/vmprotect-3.5.1.git. DMCA https://huihui.cat/mirrors/vmprotect-3.5.1 - There are download options but they all hang https://git.nadeko.net/Fijxu/vmprotect-source - No options to download https://pixeldrain.com/u/fKn1dZqK - too many connections. I tried few days
-
there are 3 options above, which one failed for you? how about trying others....
-
I am not able to download. is there any other way?
-
 DeLuks changed their profile photo
DeLuks changed their profile photo -
This project is mirrored from https://github.com/jmpoep/vmprotect-3.5.1.git. https://huihui.cat/mirrors/vmprotect-3.5.1 https://git.nadeko.net/Fijxu/vmprotect-source (someone is fighting and DMCA-ing (removing) all VMP related repos on github!) and a downloadable copy https://pixeldrain.com/u/fKn1dZqK
-
Can I have this source code back, my friend?
-
View File .NET Reactor v7.3 (Embedded DLL's) File protected by .NET Reactor v7.3 having Code Virtualization enabled. By nature the application using Dependency Injection (this time heavily developed), the 3rd party files embedded to main exe (see shot2), in addition System.Data.SQLite.dll lying near application. Find registration combination and reply it with the success message! Custom antidebugger Submitter whoknows Submitted 06/26/2025 Category UnPackMe (.NET)
-
15 downloads
File protected by .NET Reactor v7.3 having Code Virtualization enabled. By nature the application using Dependency Injection (this time heavily developed), the 3rd party files embedded to main exe (see shot2), in addition System.Data.SQLite.dll lying near application. Find registration combination and reply it with the success message! Custom antidebugger - Earlier
-
@CreateAndInject WindowsFormsApplication37-src.rar
-
 v.0.0.9.1 exeinfope.zip
v.0.0.9.1 exeinfope.zip -
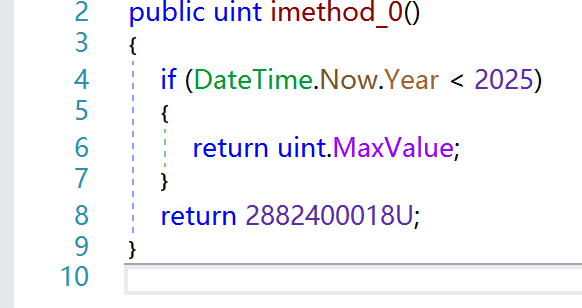
Why the code seems strange? What is Dependency Injection? Which the 3rd party files does the unapckme use? uint num = interface4_0.imethod_0();

-
View File Eazfuscator.NET v2025.1 File protected by Eazfuscator.NET v2025.1 having Code Virtualization enabled. By nature the application using Dependency Injection, the 3rd party files embedded to main exe. Find registration combination and reply it with the success message! Codebase improved a little bit versus reactor73 target. Submitter whoknows Submitted 06/24/2025 Category UnPackMe (.NET)
-
11 downloads
File protected by Eazfuscator.NET v2025.1 having Code Virtualization enabled. By nature the application using Dependency Injection, the 3rd party files embedded to main exe. Find registration combination and reply it with the success message! Codebase improved a little bit versus reactor73 target. -
@CreateAndInject A small tut of how you did it?
-
its ldstr handler from the virtualization